Intelligence is an adaptive process that requires an environment on which it can act. To uncover if neurons have independent intelligence requires closed loop experiments in a non-random environment.
In the last post I talked about how our current experimental paradigms are not designed to understand if neurons have independent adaptive intelligence. So, how can we design experiments to uncover neuronal intelligence? We need controlled that allow for replication of results? The key insight is that any adaptive system needs an environment to adapt to. Imagine if we lived in an environment that was entirely random and on which we could have no meaningful impact – what would learning, thinking or intelligence even mean? There have been extensive arguments made that we can only understand our cognition if we consider how it is embedded into its environment (called embodied, embedded cognition); we cannot understand the thought of our mind without considering the environment within which and about which the mind thinks. If this is the case with our cognition, why also would not this be the case with individual neurons in our brain?
Embedded experiments in a non-random environment
The question is then: How can we create the simplest possible experimentally controlled environment for individual neurons? Let us first observe that the two key properties of any environment are:
- i) an environment is mostly predictable; it is something that can be explored and learned about but then one can act within it, knowing with a certain level of confidence what will happen next (this is unlike our traditional maximally reductionist experimental design, which insists on full randomness and maximal lack of predictability with the exception of one single variable that is being investigated).
and
- ii) the agent has means of acting on this environment and by doing so, the agent exerts changes on that environment. These changes in turn, affect the sensory inputs that the agent will receive from the environment, which will in turn affect the actions of the agent back onto the environment. And so on. (again, this is not allowed in our classical experiments.)
How do we create a predictable environment within a classical electrophysiological experiment? What is the simplest possible way to turn our existing experimental setups into environments in which neurons can “live” by observing, acting, changing the environment, and learning?
Demonstrating intelligence requires closed loop experiments
One way is by constructing closed loop experiments. In closed loop experiments the stimuli delivered to neurons must depend on the responses the neurons generated in the past. That way the loop is closed: stimuli affect neurons; neurons affect stimuli. This give neurons the opportunity to control which kind of stimuli they receive. This also gives the experimenter the opportunity to investigate what neurons “want”. Sounds familiar? This is exactly what you may need to do when observing and investigating animal behavior in the wild.
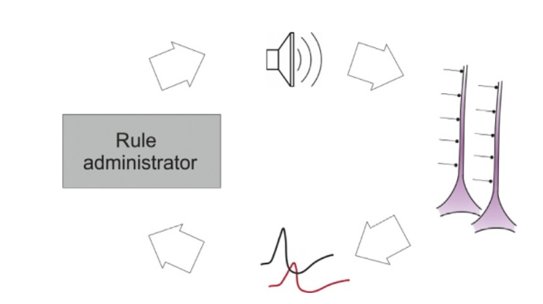
Figure 1: The main components of a closed loop experiment: the stimulus delivered to neurons (sound in this example), neurons create responses in form of action potentials, information about action potentials is fed into a computer to generate new stimuli. And the loop is closed. Rule administrator is a piece of software that simulates the properties of the environment in which neurons “live”. Experimenter makes changes to rule administrators in order to expose neurons to new environments.
An idea for a closed loop experiment
What would that look like in an actual lab? Let us assume that as input we present images. In vision experiments this may be for example, lines, gratings or other images presented on a screen. Let us also presume that as the output we record the spiking activity of a single neuron in a visual system. Finally, let us also presume that this experiment is performed under anesthesia to take out any possibility that conscious decisions made by the animal/human control the behavior of the neuron. The basic paradigm is the same also for experiments in vitro (see Nikolić 2016 for details).
The simplest possible closed loop experiment would look like this: Every time the neuron generates a spike the stimulus moves one pixel to the left in the visual field, and every time a neuron stays silent for about one second or so the stimulus moves one pixel to the right. The question is: where would the stimulus end up after say, 10 minutes? If we perform a series of experiments with randomly varying only the starting point of the stimulus, what would we observe as a general pattern?
Would the stimulus end up at random places all over the screen? If so, then nothing especially intelligent was going on with that neuron’s activity.
However, another (earth-shattering) possibility is that a neuron takes control of a stimulus position and moves it to its “preferred” location. For example, if we start the experiment locating the stimulus near the receptive filed of the neuron, it may happen so that the neuron acts in a way as to move the stimulus towards the receptive field. In that case, if the initial location is such that more action potentials will repel the stimulus away from the receptive field while silence lets the stimulus drift towards the receptive filed, the neuron may “decide” to stay silent so as to let the stimulus slide in. And, when the experimenter changes the location of the stimulus such that only spiking activity moves the stimulus inside the receptive field, the neuron may recognize the opportunity and increase its firing rate, until the stimulus sits at the preferred location.
If we observe such a result in an experiment, these two conclusions can be made:
(i) Neurons are likely much smarter than what connectionism tells us, as they observe goal-oriented behavior and preferences.
and
(ii) The preference in this experiment is to be stimulated.
The fact that we can potentially draw two possible conclusions we can potentially draw from such an experiment is especially important. The first conclusion refers to a rigorously tested hypothesis. If the first one is true, then the second conclusion allows us to learn something new—to expand the knowledge about neurons; namely, in this example, that neurons prefer to be stimulated. It could also be the case that neurons do not like being stimulated and hence, repel stimuli away from their receptive fields. Currently, such things are utterly unknown because we do not employ closed loop experimentation. There is also a lot more that can be done with such experiments. And a lot more can be learned if the first conclusion turns out to be true (see Nikolić 2016 for details).
Recall that in our everyday life we continuously interact with the environment in a closed-loop manner. Even when it looks like we are passively observing the environment, we are often tacitly engaged into a closed loop. A simple act of turning our head makes a difference to which information we will receive from the environment. After every action, no matter how small, the environment gives us a new input that somehow depended on that action. From birth on we are involved in closed loops, and we never exit them. This is the natural habitat of our intelligence. Hence, our minds are tuned to display their powers best in exactly such setups. Closed loop experiments may be exactly what we need to decipher the secrets of the brain, to understand why the responses are so variable, why neurons act spontaneously and whether they are indeed independently intelligent.
References
Nikolić, D. (2016). Testing the theory of practopoiesis using closed loops. In Closed Loop Neuroscience (pp. 53-65).
So do your experiments look to increase memory? Or activate more of the brain than what is already used? If so where do you volunteer to be part of the experiment?